Highlights
We introduce a framework for completing the code in your repository more accurately while bringing near 100% speedup compared to previous RAG-based methods.
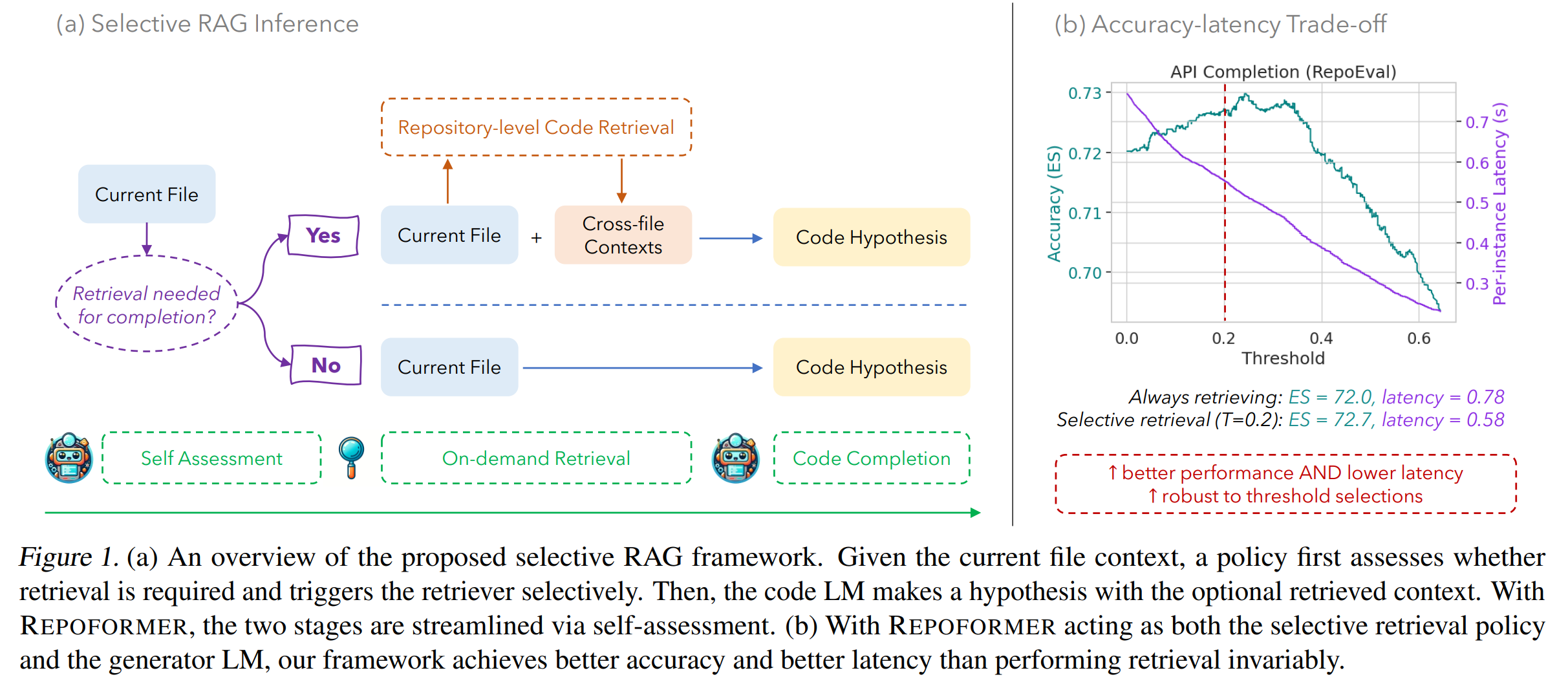
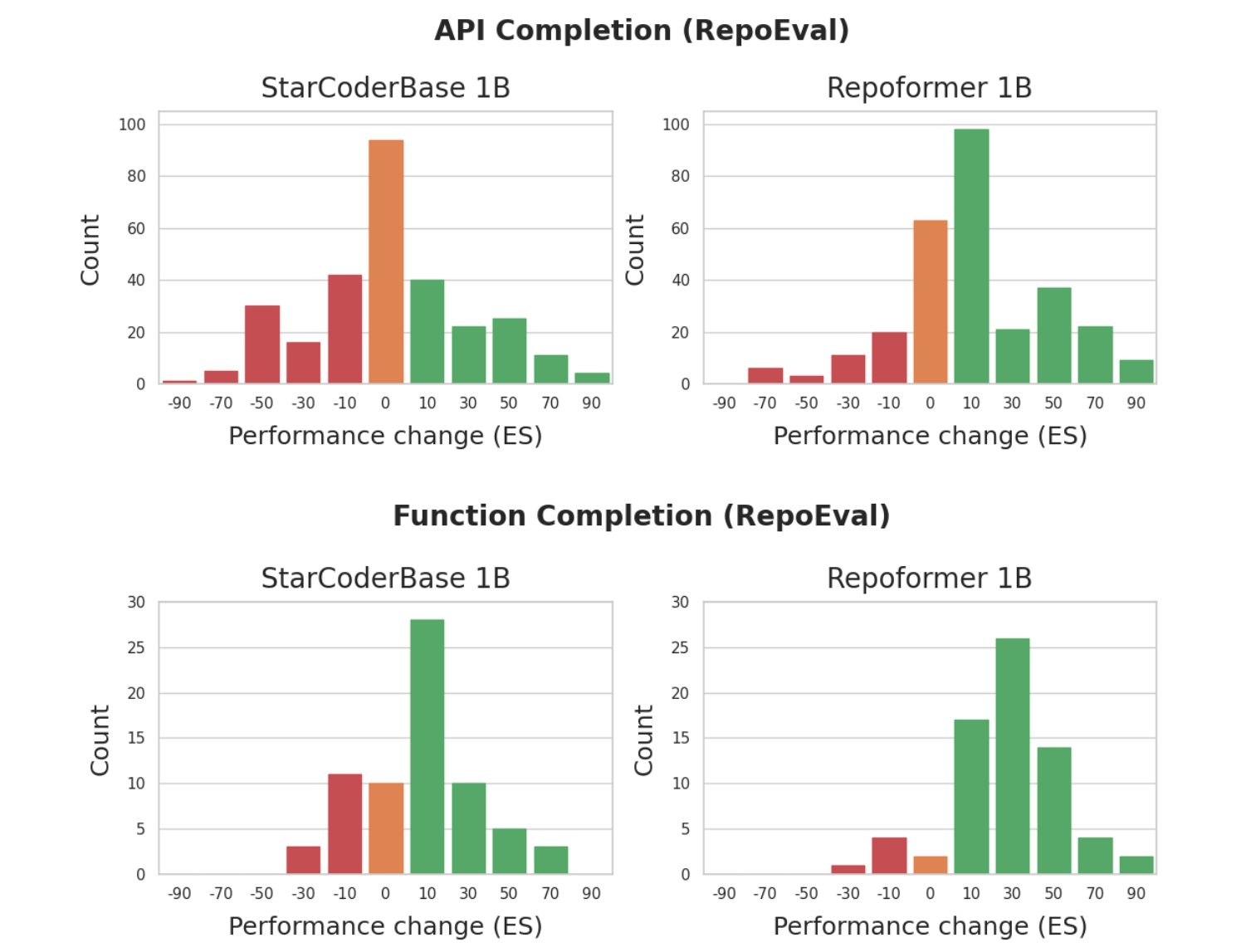
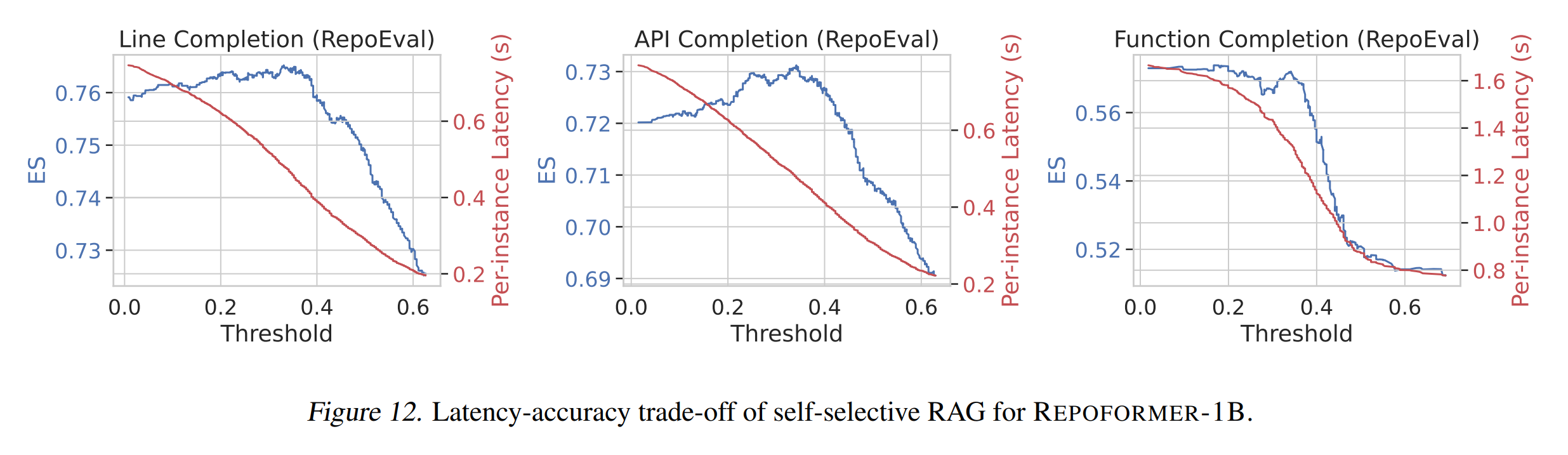
The framework is powered by Repoformer, a fine-tuned code LM capable of self-evaluating whether repository-level retrieval is required, selectively triggering retrieval, and robustly leveraging the retrieved contexts. Our Repoformer-3B performs on par compared to state-of-the-art repository-level code completion system with StarCoder (16B).
Key features:
- Performance-oriented selective retrieval. Repository-level retrieval is informative yet very costly. Repoformer learns to trigger it only when it is likely to improve code completion.
- Enhanced robustness to retrieved contexts. Repoformer learns to extract the most important information from retrieval, avoiding being distracted by irrelevant context.
- Self-supervision. The training process of Repoformer is purely self-supervised.
- Generalizability. Our framework greatly improves the accuracy and inference latency on various completion granularity and languages. Repoformer can serve well as a plug-and-play retrieval policy for RAG systems with different black-box code LMs as the generation model.